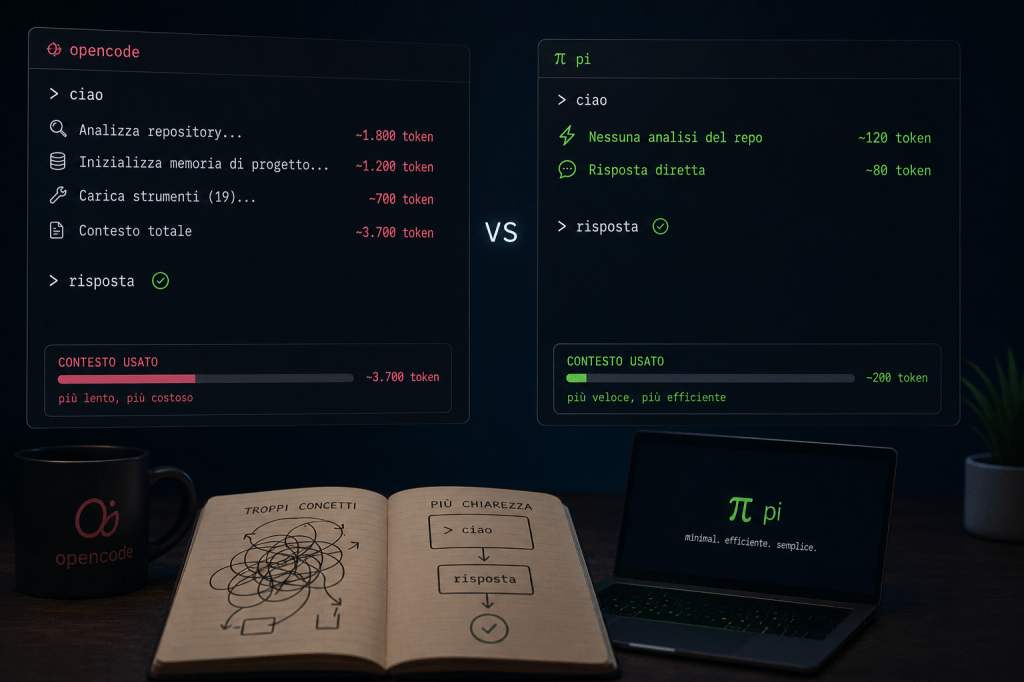
Apri OpenCode, scrivi “ciao”. Prima ancora di risponderti, l’agente analizza il repository, inizializza la memoria di progetto, consuma circa diecimila token — lo 0,6% del contesto disponibile, per un saluto. Apri pi, scrivi la stessa parola, e la risposta arriva senza che nulla venga allocato. Non è un dettaglio da changelog. È la prova empirica di una tesi che da gennaio sto verificando a modo mio, confrontando RTK, Headroom, Caveman e CodeGraph per risparmiare token su Claude Code: vince l’organizzazione, non la compressione. Pi arriva alla stessa conclusione da una direzione opposta. Non comprime niente. Toglie quello che genera il problema.
Il video di Simone Rizzo che ho guardato in questi giorni mette pi e OpenCode uno di fianco all’altro su tre compiti reali, e i numeri raccontano una storia coerente. Sulla generazione di una landing page a parità di prompt e modello, pi chiude il task usando il 3% del contesto contro il 4% di OpenCode — differenza minima sulla carta, sostanziale se il task si ripete cento volte al giorno. Sull’analisi di log con un modello locale, Gemma 4 12B via LM Studio, pi invia circa 1.800 token contro i 9.709 di OpenCode per lo stesso compito, generando a 25,7 token al secondo contro 18. La causa non è un trucco di ottimizzazione: è che OpenCode porta con sé diciannove strumenti predefiniti, server MCP, modalità di pianificazione, sotto-agenti — tutto attivo di default, tutto da leggere a ogni turno. Pi ne porta quattro. Il resto, se serve, lo costruisce l’agente stesso leggendo la documentazione delle estensioni e configurandolo su richiesta, comandi dedicati compresi. Non è minimalismo come gusto estetico: è un system prompt che resta sotto le mille parole, e ogni token risparmiato in fase di prefill è un token che non paghi e non aspetti.
C’è una scelta filosofica dietro, non solo ingegneristica. La sigla “what we didn’t build” che gira intorno a pi rovescia la logica con cui quasi tutti gli strumenti agentici sono stati pensati negli ultimi due anni: aggiungere capacità finché il modello non si perde nella propria stessa cassetta degli attrezzi. Qui succede l’opposto — meno concetti nativi, meno superficie su cui l’agente può inciampare da solo, meno inizializzazioni che nessuno ha chiesto. Il fatto che un progetto di orchestrazione complesso come OpenClaw abbia scelto proprio pi come scaffold sottostante non è casuale: quando costruisci sopra, vuoi una base che non ti porti dietro decisioni prese da altri.
La seconda scoperta della settimana completa il quadro in modo quasi scomodo per quanto torna comoda. Atomic Chat, nata come app per Mac e oggi disponibile anche su Windows e iPhone, espone un server compatibile OpenAI su localhost:1337/v1: qualunque agente che parli quel protocollo — pi compreso — può puntarci sopra senza una riga di collante in più. Gemma 4 E4B ci entra in circa tre gigabyte, con decoding speculativo che su Apple Silicon arriva fino a tre volte più veloce. Messa insieme alla minimalità di pi, la combinazione produce qualcosa che fino a poco fa non avevo: un livello locale, a costo zero, per tutto ciò che è ripetitivo o a basso rischio — un saluto, una validazione sintattica, una bozza da buttare — senza nemmeno la tentazione di farlo passare per un provider remoto a pagamento.
Va detto con chiarezza, però, che i numeri di Rizzo sul test locale (1.800 token, 25,7 token al secondo) sono stati misurati su Gemma 4 12B, non sulla E4B da tre gigabyte che gira su Atomic Chat. Sono due modelli diversi nella stessa famiglia, un ordine di grandezza di distanza. Che la E4B regga altrettanto bene il meccanismo di pi — scoprire uno strumento mancante e auto-configurarlo leggendo la documentazione — è tutto da verificare: a quella taglia il rischio è che il modello non sappia di non sapere, e improvvisi invece di estendersi.
Boh, va detto: sono quattro mesi che provo CLI agent come fossero figurine, e il rischio di scambiare la curiosità per produttività è reale quanto i numeri qui sopra. La domanda onesta è se questa coppia — pi più Atomic Chat — la uso davvero entro la settimana sui task ripetitivi che tengo da parte, o se resta l’ennesimo esperimento parcheggiato. Per ora l’idea che mi convince di più non è sostituire il setup principale che uso per i task complessi, ma affiancargli un secondo motore, più piccolo e più povero di concetti, per tutto quello che non merita il peso di un harness completo. I dati del video di Rizzo dicono che la differenza si misura in token e in secondi. Quanto valga in pratica, lo scopro solo aprendo il terminale e smettendo di guardare benchmark altrui.
Riferimenti
[1] S. Rizzo, Perché Tutti Stanno Passando a Pi Agent, YouTube, 2026. Benchmark comparativo pi/OpenCode su generazione codice, interazione minima e analisi log con modello locale. URL: http://www.youtube.com/watch?v=tdG6u999wzU
[2] Mario Zechner: AI Coding Agents Are Producing ‘Garbage’ — and the Industry Needs to Slow Down, BigGo Finance, aprile 2026. Architettura minimale di pi (quattro strumenti integrati) e contesto del progetto OpenClaw. URL: https://finance.biggo.com/news/b8d5eb1ebdebee57
[3] AtomicBot-ai, Atomic-Chat (repository), GitHub. Server locale OpenAI-compatible su localhost:1337/v1 e integrazione con agenti esterni. URL: https://github.com/AtomicBot-ai/Atomic-Chat
[4] Atomic Chat: Free Local AI Chat for Mac, Windows & iPhone, atomic.chat. Pagina prodotto, piattaforme supportate, modelli disponibili. URL: https://atomic.chat/

Leave a comment