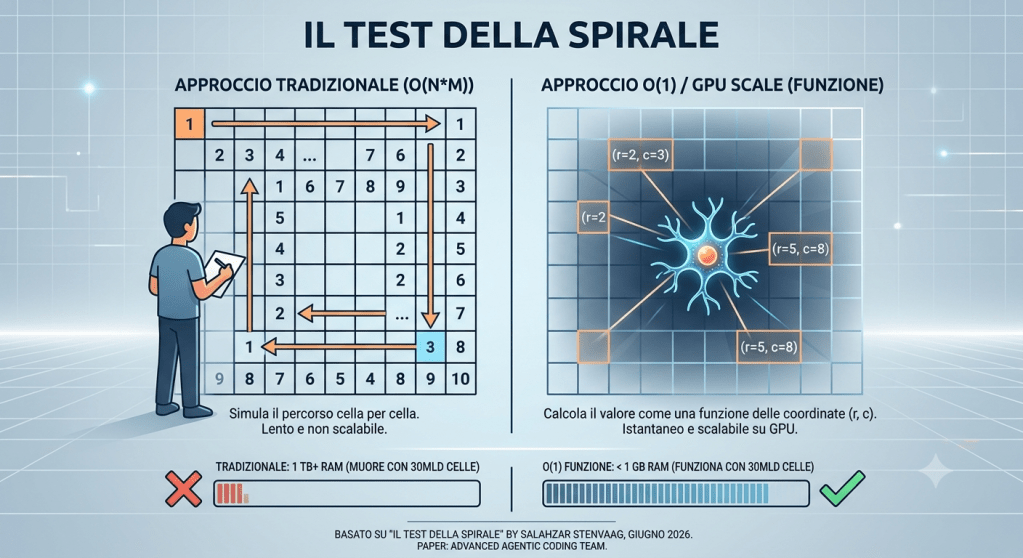
Il modo più rapido per capire se un programmatore pensa o esegue è dargli una matrice da riempire a spirale.
Usavo questo problema nei colloqui tecnici. Non come trabocchetto — come specchio. La matrice era piccola (10×10, al massimo 20×20), i numeri andavano da 1 a N×M disposti seguendo la traiettoria classica: partenza dall’angolo in alto a sinistra, direzione destra, poi giù, poi sinistra, poi su, poi di nuovo dentro. Il candidato aveva carta, penna, e il tempo che voleva.
Il 90% simulava. Prendeva un cursore immaginario, lo muoveva fisicamente lungo la griglia, aggiornava la cella corrente, teneva traccia della direzione. Corretto. Funzionante. Ma c’era una soluzione geniale e completamente scalabile su GPU come fanno adesso i modelli LLM e l’AI.
Ogni tanto — raramente, tre o quattro volte in anni di colloqui — qualcuno si fermava, guardava la griglia vuota per qualche secondo, e chiedeva: “Posso calcolare il valore di una cella qualsiasi senza sapere cosa c’è nelle celle vicine?”
Quello che intuivano è che la spirale non è un percorso ma una funzione. Ogni cella ha coordinate (r, c). La distanza minima dai quattro bordi dà il livello concentrico — il guscio in cui la cella si trova. Dal livello si ricava il valore iniziale di quel guscio. Dal valore iniziale e dalla posizione nel perimetro si ricava il numero esatto. Zero iterazioni. Zero memoria delle celle precedenti. O(1) in spazio, nel senso che non serve tenere a mente nient’altro che la posizione corrente.
Un paper uscito questa settimana — Calcolo di Matrici a Spirale ad Altissime Prestazioni, Advanced Agentic Coding Team, giugno 2026 — formalizza questo trucco con rigore matematico e poi lo spinge all’estremo: una matrice da 100.000 × 300.000 celle, 30 miliardi di elementi, elaborata in 0,833 secondi su GPU NVIDIA tramite CUDA.
Per capire perché la differenza tra i due approcci non è una questione di ottimizzazione ma di sopravvivenza del programma, basta il calcolo della memoria. In Python standard ogni intero piccolo occupa 28 byte di struttura interna — contatore di riferimenti, puntatore al tipo, dimensione — più 8 byte di puntatore nella lista che lo contiene. Trenta miliardi di celle per 36 byte: 1,08 terabyte di RAM. Su un sistema con 64 GB disponibili il programma non va lento — muore. Il kernel del sistema operativo uccide il processo per preservare il sistema, oppure la macchina entra in paralisi cercando di usare il disco come memoria, un ciclo da cui non si torna nel giro di qualche minuto.
L’approccio O(1) aggira il problema in radice: non alloca niente, calcola ogni valore al volo, accumula un unico numero come verifica. Il disco non entra nemmeno nell’equazione.
Vabbè, fin qui è ottimizzazione della memoria — cosa nota, apprezzabile. La parte che mi ha convinto che il paper valesse la lettura è la sezione sulla validazione matematica.
Il checksum scelto per verificare la correttezza è uno XOR cumulativo di tutti gli elementi della spirale. Per 30 miliardi di celle il risultato atteso è esattamente 30.000.000.000. Non è una coincidenza né un errore di implementazione — è una proprietà algebrica: quattro interi consecutivi che iniziano da un multiplo di 4 si azzerano sempre nello XOR (i bit superiori si cancellano quattro volte; i due bit bassi fanno 00⊕01⊕10⊕11=00). Trenta miliardi è divisibile per 4, quindi il risultato finale è K stesso.
È lo stesso ragionamento del mio test del colloquio, guardato dall’altra parte: il modo più veloce per verificare che il calcolo sia corretto non è rieseguire il calcolo — è sapere a cosa deve essere uguale a priori, per proprietà strutturale. Chi lo capisce non controlla cella per cella. Chi non lo capisce stampa la matrice e conta.
Il paper procede poi attraverso la parallelizzazione su CPU multi-core con OpenMP — dove la riduzione XOR viene distribuita tra i thread e riassemblata senza condizioni di corsa — fino al kernel CUDA con warp shuffle, uno scambio di valori direttamente tra registri fisici dei thread contigui, senza passare per la memoria condivisa.
C’è un dettaglio tecnico che vale la pena nominare perché è controintuitivo: la versione finale usa codice “senza salti condizionali” — calcola sempre tutti e quattro i possibili bordi della spirale per ogni cella, poi seleziona il risultato corretto con moltiplicazioni booleane invece di istruzioni if-else. Questo guadagna il 22% di prestazioni rispetto alla versione con rami tradizionali.
Perché? Perché nelle GPU i salti condizionali tra thread dello stesso gruppo — thread che prendono rami diversi — bloccano la pipeline dell’intero gruppo. Il costo di calcolare tre percorsi inutili è inferiore al costo di gestire la divergenza. Su una CPU è il contrario. Una GPU non è una CPU con diecimila core: è una macchina pensata per fare la stessa cosa su dati diversi, e i salti rompono quella coerenza.
La spirale resta, nel 2026, quello che era quando la usavo nei colloqui: un problema che sembra di percorso e invece è di struttura. Chi lo simula risolve il caso. Chi lo astrae risolve la classe.
Quello che il paper aggiunge è la dimostrazione che quell’astrazione, portata fino in fondo, scala da qualche millisecondo su una matrice giocattolo a sotto-secondo su trenta miliardi di celle. Il salto non è di hardware — è di modello mentale. L’hardware poi fa il resto, molto velocemente.
Riferimenti
[1] Calcolo di Matrici a Spirale ad Altissime Prestazioni: Dalle Limitazioni Fisiche della Memoria all’Esecuzione Parallela Sub-Secondo su GPU, giugno 2026. Vedi sotto. Contiene formule matematiche complete, codici di riferimento in Python, C/OpenMP e CUDA, e benchmarking su AMD Ryzen 9 5900X + NVIDIA RTX 3060.
[2] M. Harris, Optimizing Parallel Reduction in CUDA, NVIDIA Developer Technology Whitepaper, 2007. [PDF] Base teorica per la riduzione con warp shuffle citata in [1].
URL: https://developer.download.nvidia.com/compute/cuda/1.1-Beta/x86_website/projects/reduction/doc/reduction.pdf

Leave a comment