perché il wiki-LLM batte il RAG sotto i mille documenti
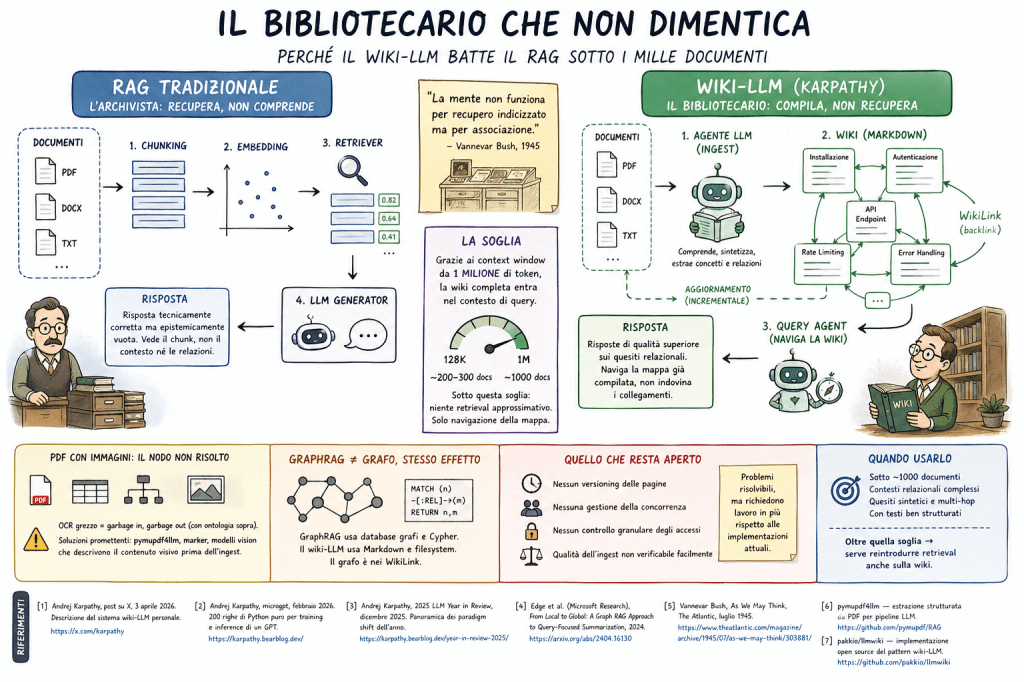
Chiunque abbia messo su un sistema RAG con Ollama sa come va. Carichi i documenti, costruisci gli embedding, configuri il retriever, fai le prime query e — per i casi semplici — funziona benissimo. Poi arriva la seconda settimana, quella in cui il corpus ha un po’ di spessore, e inizi a capire dov’è il problema. Non nella risposta sbagliata. Nella risposta tecnicamente corretta ma epistemicamente vuota: il sistema restituisce il chunk giusto, ma non sa che quel chunk è la premessa di un’altra sezione in un altro documento, che a sua volta contraddice un’affermazione fatta nel manuale aggiornato di tre mesi fa. Il RAG classico non ragiona — recupera. È un archivista con un’ottima memoria fotografica e zero comprensione del catalogo.
Il 3 aprile 2026, Andrej Karpathy ha pubblicato su X la descrizione di un sistema diverso. Non un’altra variante di pipeline RAG. Una cosa concettualmente opposta: invece di indicizzare i documenti per recuperarli al momento della query, un agente LLM li legge e costruisce — subito, al momento dell’ingest — una rete di pagine Markdown interconnesse. Una wiki. Il modello scrive gli articoli, crea i backlink tra i concetti, aggiorna le voci esistenti quando arriva materiale nuovo. Alla query, l’agente non fa retrieval su embedding: naviga una mappa già compilata.
Sedici milioni di visualizzazioni in pochi giorni. Il numero dice che non era solo lui ad aver il problema.
La stratificazione che cambia tutto
La differenza non è estetica. È dove avviene il lavoro cognitivo.
Nel RAG tradizionale, la struttura relazionale tra i concetti non viene mai esplicitata: rimane latente negli embedding, approssimata dal coseno tra vettori. Funziona per le domande localizzate — “qual è la procedura X?” — e cade sui quesiti sintetici: “come si relaziona X con Y nel contesto del progetto Z?” Il retriever porta chunk, il generatore deve ricostruire la relazione ogni volta, da zero, con il rischio di allucinare i ponti mancanti.
Il wiki-LLM sposta quel lavoro all’ingest. L’agente che processa un documento non lo spezzetta in chunk — lo comprende e lo decompone in entità concettuali con relazioni esplicite. Un manuale tecnico diventa dieci pagine wiki con WikiLink tra loro. Il secondo documento che parla degli stessi concetti aggiorna le pagine esistenti invece di coesistere in un vettore parallelo. Il risultato è una stratificazione ontologica incrementale: ogni ingest non aggiunge dati, costruisce conoscenza.
Vannevar Bush l’aveva intuito nel 1945, nel suo saggio sul Memex: la mente non funziona per recupero indicizzato ma per associazione. Aveva ragione sulla struttura, torto sulle macchine disponibili. Ottant’anni dopo, le macchine ci sono.
La soglia dei mille documenti e i contesti da un milione di token
C’è un vincolo tecnico che rende questo approccio praticabile solo sotto una certa dimensione del corpus, e lo stesso vincolo che ha spostato quella dimensione abbastanza in su da renderlo interessante per uso reale.
Il punto di forza del sistema è che l’indice della wiki — la lista di tutte le pagine con i loro riassunti — entra nel context window dell’agente di query. Questo permette al modello di capire cosa esiste, cercare le pagine rilevanti, navigare i backlink e rispondere senza mai fare retrieval approssimativo. Con contesti da 128K token, la soglia era intorno ai 200-300 documenti. Con i modelli attuali da un milione di token, si arriva a circa mille documenti — che in ambito enterprise è una base documentale tutt’altro che marginale: il manuale di un prodotto complesso, la knowledge base legale di una PMI, la documentazione interna di un progetto pluriennale.
Oltre quella soglia, il vantaggio si erode: serve reintrodurre retrieval anche sulla wiki stessa, e si ricade nella logica RAG con un layer aggiuntivo di complessità. Ma sotto, il sistema è pulito, controllabile, e produce risposte di qualità genuinamente superiore sui quesiti relazionali.
PDF con immagini: il nodo non risolto
L’approccio funziona bene su testo. I documenti aziendali reali sono quasi tutti PDF con tabelle, diagrammi, screenshot, flow chart. Questo è il punto su cui nessuna implementazione attuale, inclusa llmwiki, è ancora matura.
Il pre-processing conta quanto l’agente. Un OCR grezzo che spezza le tabelle in righe sconnesse produce pagine wiki inutili — garbage in, garbage out, con ontologia sopra. Strumenti come pymupdf4llm o marker gestiscono meglio il layout; per i diagrammi, un modello vision che descrive il contenuto visivo prima dell’ingest è la strada più promettente. Non è un problema insolubile, ma è un problema che richiede un layer aggiuntivo che l’implementazione di base non include.
GraphRAG, senza il grafo come struttura dati
Microsoft ha rilasciato GraphRAG nel 2024, con un’architettura che costruisce esplicitamente un knowledge graph prima del retrieval. Stessa intuizione di fondo, implementazione pesante: richiede pipeline di entity extraction, database grafi, query in Cypher o simili. Il costo operativo è alto, la manutenzione non banale.
Il wiki-LLM di Karpathy raggiunge un effetto analogo con Markdown e un filesystem. Il grafo non è una struttura dati separata — è nei WikiLink tra le pagine. L’agente non ha bisogno di Cypher: legge file come li leggerebbe un umano. Questo è il tratto più Karpathiano dell’approccio, nel senso autentico del termine: la soluzione più semplice che risolve il problema, non quella più impressionante da presentare in una slide.
Quello che resta aperto
Per uso enterprise, le lacune attuali sono reali. Nessun versioning delle pagine: se l’agente riscrive male una voce, non c’è storia. Nessuna gestione della concorrenza: due ingest simultanei si calpestano. Nessun controllo granulare degli accessi: documenti con diversi livelli di riservatezza finiscono nella stessa wiki. Sono problemi risolvibili — SQLite con WAL, lock file, metadati sulle pagine — ma richiedono lavoro che le implementazioni attuali, inclusa llmwiki, non hanno ancora fatto.
C’è poi una questione più sottile sulla qualità dell’ingest. L’agente scrive pagine, ma non c’è modo semplice di sapere se ha perso concetti importanti o ha introdotto distorsioni nel processo di sintesi. Un linting pass che verifica consistenza interna è utile, ma non è una garanzia. La wiki cresce organicamente, e come ogni crescita organica può sviluppare errori strutturali che diventano visibili solo tardi.
Detto questo: chiunque abbia passato settimane a debuggare un RAG con embedding instabili su italiano, domande che tornano chunk irrilevanti, e risposte che suonano plausibili ma sono costruite sul nulla — quella persona capisce al volo perché un sistema che compila la conoscenza invece di recuperarla vale la pena di esplorare. Anche con le sue lacune attuali.
Riferimenti
[1] Andrej Karpathy, post su X, 3 aprile 2026. Descrizione del sistema wiki-LLM personale. URL: https://x.com/karpathy (post originale)
[2] Andrej Karpathy, microgpt, febbraio 2026. 200 righe di Python puro per training e inference di un GPT. URL: https://karpathy.bearblog.dev/
[3] Andrej Karpathy, 2025 LLM Year in Review, dicembre 2025. Panoramica dei paradigm shift dell’anno. URL: https://karpathy.bearblog.dev/year-in-review-2025/
[4] Edge et al. (Microsoft Research), From Local to Global: A Graph RAG Approach to Query-Focused Summarization, 2024. URL: https://arxiv.org/abs/2404.16130
[5] Vannevar Bush, As We May Think, The Atlantic, luglio 1945. Il Memex come precursore del knowledge management associativo. URL: https://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/
[6] pymupdf4llm — estrazione strutturata da PDF per pipeline LLM. URL: https://github.com/pymupdf/RAG
[7] pakkio/llmwiki — implementazione open source del pattern wiki-LLM. URL: https://github.com/pakkio/llmwiki

Leave a comment