
Individuare le Allucinazioni nelle IA
Introduzione: La sfida delle allucinazioni nell’IA
Uno dei problemi più critici nell’uso dei modelli linguistici di grandi dimensioni (LLM) è il fenomeno delle allucinazioni – quando un modello genera informazioni che appaiono plausibili ma sono fattualmante errate o inventate. Questo fenomeno rappresenta un ostacolo significativo all’adozione di soluzioni basate su IA in contesti che richiedono alta affidabilità come sanità, finanza o sistemi legali.
In questo articolo, esploreremo come le log-probabilità (logprob) rappresentino uno strumento potente per identificare potenziali allucinazioni e migliorare l’affidabilità delle IA generative.
Cosa sono le LogProb e come funzionano
Le log-probabilità sono il logaritmo naturale della probabilità assegnata dal modello a una particolare scelta di token (parola o parte di parola). Quando un modello linguistico genera testo, in ogni posizione deve decidere quale sarà il prossimo token, e assegna a ciascuna possibilità una probabilità.
Proprietà matematiche chiave:
- Il valore logprob è sempre ≤ 0 (essendo un logaritmo di un numero tra 0 e 1)
- Logprob = 0 corrisponde a confidenza massima (100%)
- Logprob = -1 corrisponde a circa 37% di confidenza
- Logprob = -2 corrisponde a circa 14% di confidenza
- Più il valore è vicino a zero, maggiore è la confidenza
La formula per convertire un logprob in percentuale di confidenza è:
confidenza_percentuale = e^(logprob) * 100
Dove e è il numero di Eulero (circa 2,718).
Metodologia: Analisi della confidenza per frase
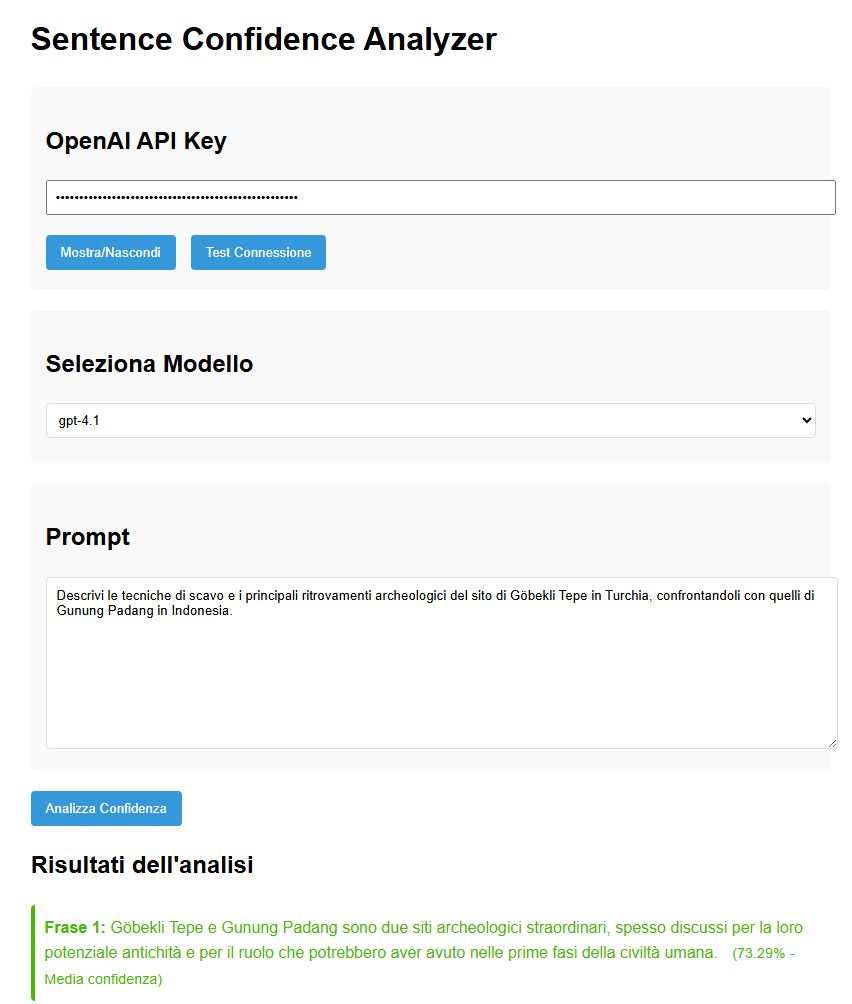
Nella nostra analisi abbiamo utilizzato un approccio innovativo per visualizzare la confidenza non a livello di singoli token ma di intere frasi, rendendo l’analisi più intuitiva e semanticamente significativa:
- Estrazione dei logprob tramite l’API di OpenAI con il parametro
logprobs=True - Aggregazione dei token in frasi complete attraverso analisi del testo
- Calcolo della confidenza media per ciascuna frase
- Visualizzazione cromatica dal rosso (bassa confidenza) al verde (alta confidenza)
Questo approccio permette di identificare rapidamente quali parti di una risposta sono più affidabili e quali potrebbero contenere allucinazioni.
Studio comparativo: GPT-4o, GPT-4o-mini e GPT-4.1
Abbiamo condotto un esperimento sottoponendo la stessa domanda sui siti archeologici di Göbekli Tepe e Gunung Padang a tre diverse versioni dei modelli GPT, analizzando come variano i pattern di confidenza.
GPT-4o: Il rilevatore di allucinazioni più calibrato
Il modello GPT-4o ha mostrato una calibrazione epistemica notevolmente realistica:
- Gradiente geografico di confidenza: alta sicurezza (70-90%) sulle informazioni relative a Göbekli Tepe (sito ampiamente studiato) e confidenza significativamente inferiore (50-70%) per Gunung Padang (sito più controverso)
- Confidenza zero su affermazioni particolarmente incerte (come specifiche tecniche di scavo)
- Alta differenziazione tra fatti consolidati e speculazioni

GPT-4o-mini: Omogeneo con peculiarità strutturali
GPT-4o-mini ha rivelato un pattern completamente diverso:
- Range di confidenza più limitato (37-100%)
- Uniformità tra fatti consolidati e speculazioni
- Picchi anomali del 100% sui numeri degli elenchi puntati
- Assenza di frasi con confidenza prossima allo zero

GPT-4.1: L’accademico cauto
GPT-4.1 ha mostrato una strategia di confidenza più simile a quella di un ricercatore prudente:
- Una sola frase con alta confidenza (>85%), focalizzata su descrizioni visive concrete
- Prevalenza di frasi a bassa confidenza (50-70%)
- Confidenza zero mirata su punti scientificamente controversi
- Approccio “accademicamente distaccato” con linguaggio qualificante
Perché questo caos è utile: l’applicazione pratica
Tutta questa complessità e varietà nei pattern di confidenza ha un’importanza pratica fondamentale:
1. Identificazione visiva delle allucinazioni
La colorazione delle frasi basata sulla confidenza (rosso per bassa confidenza, verde per alta) permette di identificare a colpo d’occhio quali parti di una risposta potrebbero contenere allucinazioni. Questa visualizzazione intuitiva consente anche a utenti non esperti di valutare criticamente le risposte dell’IA.
2. Filtraggio automatico delle risposte
È possibile implementare sistemi di filtraggio che:
- Segnalano all’utente frasi con confidenza sotto una certa soglia (es. <60%)
- Richiedono verifiche aggiuntive per affermazioni con bassa confidenza
- Eliminano completamente contenuti con confidenza estremamente bassa (<30%)
3. Cascate di modelli più efficienti
L’analisi di confidenza permette di implementare architetture di IA a cascata dove:
- Modelli piccoli e veloci (come GPT-4o-mini) generano risposte iniziali
- Solo le parti con bassa confidenza vengono verificate da modelli più grandi
- Si ottimizzano così costi e tempi di risposta mantenendo l’affidabilità
4. Training mirato per ridurre le allucinazioni
I pattern di confidenza permettono di:
- Identificare categorie di conoscenza dove il modello produce più allucinazioni
- Creare set di addestramento specifici per migliorare quelle aree
- Valutare l’efficacia delle tecniche anti-allucinazione misurando i cambiamenti nei pattern di confidenza
Disponibilità della funzione LogProb nei principali LLM
La funzionalità di logprobs non è universalmente disponibile in tutti i modelli linguistici. Ecco un confronto della disponibilità nei principali LLM:
OpenAI (GPT-4, GPT-4o, ecc.)
- ✅ Completamente supportato
- Disponibile tramite il parametro
logprobs=Truenell’API - Permette anche di specificare
top_logprobsper visualizzare le alternative considerate
Anthropic Claude
- ❌ Non supportato ufficialmente
- Secondo diverse fonti, incluso un thread su Stack Overflow, l’API di Claude non offre l’accesso ai logprobs
- Questo è probabilmente una decisione deliberata legata alla filosofia di sicurezza di Anthropic
Google Gemini
- ⚠️ Supporto limitato/sperimentale
- Secondo discussioni nel forum degli sviluppatori Google AI, alcune versioni di Gemini supportano un parametro
response_logprobs - Tuttavia, sembra essere soggetto a forti limitazioni di quota (3 richieste al giorno) o restituire solo logprob aggregati, non a livello di token
Modelli open source (LLaMA, Mistral, ecc.)
- ✅ Generalmente supportato
- I modelli accessibili tramite API come Together.ai offrono supporto per logprobs
- Le implementazioni open source come llama.cpp permettono l’accesso diretto ai logprob quando si eseguono inferenze localmente
Conclusioni: GPT-4o come miglior rilevatore di allucinazioni
La nostra analisi comparativa suggerisce che GPT-4o potrebbe essere il modello più efficace per rilevare potenziali allucinazioni, per diverse ragioni:
- Distribuzione realistica dell’incertezza: La sua confidenza rispecchia accuratamente lo stato attuale delle conoscenze in un campo disciplinare
- Precisa identificazione dei punti critici: Assegna confidenza zero precisamente ai punti più controversi o speculativi
- Ampio range di valori: Utilizza l’intera gamma di confidenza (0-92%), permettendo una discriminazione più fine
- Allineamento con la realtà: Il suo gradiente di confidenza geografica, nel caso studiato, corrisponde perfettamente al consenso archeologico attuale
In pratica, per applicazioni che richiedono alta affidabilità, l’utilizzo di GPT-4o con visualizzazione della confidenza a livello di frase rappresenta attualmente la soluzione più promettente per individuare e mitigare il rischio di allucinazioni.
Riferimenti
- OpenAI. (2023). “Using logprobs”. OpenAI Cookbook.
- Clark, C. et al. (2022). “Measuring the Reliability of Language Models”. Transactions of the Association for Computational Linguistics.
- Together.ai. (2025). “Getting started with logprobs”. Together.ai Documentation.
- Kadavath, S. et al. (2022). “Language Models (Mostly) Know What They Know”. arXiv preprint.
- Google AI Developers. (2025). “Get logprobs at output token level”. Google AI Developers Forum.
Nota: Quest’analisi si concentra specificamente sulla confidenza come riportata dal modello stesso, che non garantisce necessariamente l’accuratezza fattuale. I modelli possono essere confidenti ma errati, o incerti ma corretti. L’uso dei logprob dovrebbe essere sempre complementare, non sostitutivo, a verifiche fattuali indipendenti.

Leave a comment