I problemi del Model Context Protocol (MCP) da una prospettiva non convenzionale. Analisi dei problemi di training di MCP, con un focus sulle reali cause sottostanti piuttosto che sui problemi di implementazione.
3 articoli che spiegano perché MCP ha problemi con il training
Introduzione
Il Model Context Protocol (MCP) di Anthropic, presentato come soluzione rivoluzionaria per la connettività tra modelli AI e sistemi legacy, sta affrontando sfide significative che vanno ben oltre i semplici problemi di implementazione. Mentre molti sviluppatori cercano soluzioni nelle configurazioni dei server o nei protocolli di comunicazione, la ricerca recente di istituzioni come Princeton, Cornell e Google DeepMind rivela che i problemi sono radicati nella natura stessa dei Large Language Models e nel modo in cui questi elaborano le nuove informazioni.
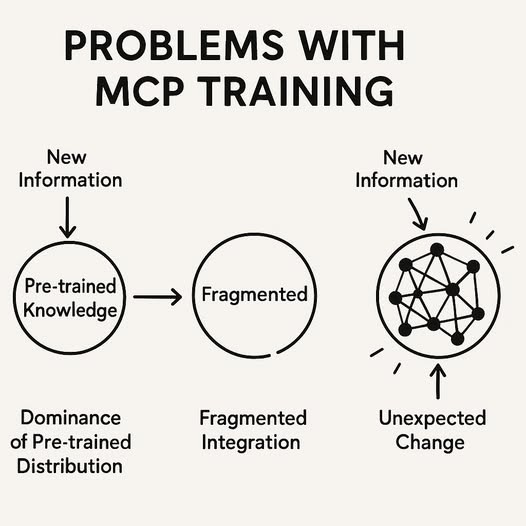
1. Il dominio delle distribuzioni di probabilità pre-addestrate
Il primo problema fondamentale del MCP non riguarda il protocollo in sé, ma come i modelli linguistici gestiscono le nuove informazioni rispetto alla conoscenza acquisita durante il pre-training.
Quando un’applicazione AI utilizza MCP per accedere a dati esterni, questi dati vengono effettivamente acquisiti dal modello, ma non vengono integrati nel processo di ragionamento con la stessa priorità della conoscenza pre-addestrata. Come evidenziato nella ricerca di Princeton, i modelli linguistici mantengono una forte “prior distribution” acquisita durante il pre-training che domina il processo decisionale.
Questo significa che anche quando MCP fornisce correttamente dati aggiornati o contestuali al modello, il modello tende a favorire le informazioni che già “conosce” dal pre-training, trattando le nuove informazioni con una priorità statistica inferiore. Il modello calcola correttamente utilizzando i nuovi dati, ma può ignorare i propri calcoli se il risultato ha una probabilità distributiva inferiore rispetto a ciò che è stato codificato durante il pre-training.
In essenza, MCP crea un canale di comunicazione senza garantire che le informazioni trasmesse vengano effettivamente utilizzate nel processo decisionale del modello.
2. L’integrazione frammentata delle nuove conoscenze
Il secondo problema cruciale riguarda come le nuove informazioni vengono integrate nel tessuto neurale del modello. La ricerca di Cornell dimostra che anche quando nuovi dati vengono incorporati attraverso continued pre-training o fine-tuning, questi non vengono integrati in modo olistico nel sistema di ragionamento del modello.
I ricercatori hanno identificato un fenomeno importante: le nuove informazioni possono essere accessibili attraverso “direct probing” (domande dirette che colpiscono esattamente il nuovo dato), ma falliscono catastroficamente in “indirect probing” (domande che richiedono il collegamento tra nuove informazioni e conoscenze esistenti per il ragionamento).
Questo significa che MCP può fornire nuovi dati che il modello è in grado di ripetere se interrogato direttamente, ma questi dati rimangono isolati dal resto della rete neurale, senza essere integrati nella struttura di ragionamento più ampia. È come avere un’enciclopedia con nuove pagine incollate in fondo che non sono referenziate nell’indice principale.
Questa mancanza di integrazione olistica limita gravemente l’utilità di MCP, poiché i nuovi dati rimangono separati dal processo decisionale principale del modello, indipendentemente dall’efficienza del protocollo di connessione.
3. Il fenomeno della permeazione della conoscenza e del bias imprevisto
Il terzo problema, evidenziato dalla ricerca di Google DeepMind, riguarda come l’introduzione di nuove informazioni può inaspettatamente “permeare” il modello in modi incontrollati, causando distorsioni impreviste nella generazione delle risposte.
Quando nuovi concetti o termini vengono introdotti in un LLM, questi tendono a “infiltrarsi” in domini completamente non correlati, un fenomeno noto come “priming”. Questo avviene perché il processo di aggiornamento di un modello attraverso gradient-based learning modifica i pesi della rete neurale in modi che non sono confinati solo alle aree pertinenti.
Per MCP, questo significa che anche quando il protocollo funziona tecnicamente come previsto, l’introduzione di nuove informazioni può avere conseguenze impreviste sul comportamento globale del modello. Nuovi termini tecnici o concetti potrebbero improvvisamente apparire in contesti completamente non correlati, diminuendo l’affidabilità complessiva del sistema.
Questo problema di permeazione dimostra che MCP, pur risolvendo il problema dell’accesso ai dati, non affronta la questione fondamentale di come questi dati vengono elaborati e integrati nel modello in modo controllato e prevedibile.
Conclusione: Verso soluzioni effettive
I problemi di MCP non sono principalmente legati all’implementazione tecnica del protocollo, ma a questioni fondamentali riguardanti l’architettura cognitiva dei LLM. I ricercatori stanno esplorando diverse soluzioni potenziali per questi problemi:
- Memory Condition Training (MCT): Una metodologia leggera di continued pre-training che cerca di migliorare l’integrazione delle nuove conoscenze nel modello, sebbene ancora in fase sperimentale.
- Stepping Stones: L’uso di “pietre di passaggio” linguistiche che aiutano il modello a comprendere dove collocare le nuove informazioni nell’architettura neurale esistente, fornendo contesto e correlazioni con concetti noti.
- Gradient Pruning: Tecniche che modificano selettivamente i pesi della rete per controllare come le nuove informazioni permeano il modello, limitando gli effetti indesiderati in domini non correlati.
- Targeted Fine-tuning: Approcci di fine-tuning mirati a domini specifici che possono aumentare la probabilità dei nuovi dati rispetto alla distribuzione pre-addestrata.
Per gli sviluppatori che utilizzano MCP oggi, la consapevolezza di questi problemi fondamentali è cruciale. Non si tratta solo di implementare correttamente il protocollo, ma di comprendere le sue limitazioni intrinseche e adottare strategie complementari per garantire che le nuove informazioni non vengano semplicemente acquisite, ma effettivamente utilizzate nel processo decisionale del modello.
Il futuro di MCP dipenderà probabilmente da una combinazione di miglioramenti nel protocollo stesso e progressi nella nostra comprensione di come i modelli linguistici integrano e utilizzano le nuove informazioni.
Riferimenti:
Zhang, L. (2025, aprile). Identifying and mitigating the influence of the prior distribution in large language models. arXiv preprint arXiv:2504.12585. http://arxiv.org/abs/2504.12585
Li, A. O., & Goyal, T. (2025, aprile). Memorization versus reasoning: How can we update the knowledge in an LLM. arXiv preprint arXiv:2504.12523. https://arxiv.org/html/2504.12523v1
Google DeepMind. (2025, aprile). How new data permeates LLM knowledge and how to dilute it. arXiv preprint arXiv:2504.09522. http://arxiv.org/abs/2504.09522v1

Leave a comment