
GPT-4.5, Claude 3.7, Grok-3, DeepSeek R1 e OpenAI o1
Negli ultimi mesi, il panorama dell’intelligenza artificiale ha visto l’emergere di nuovi potenti modelli che stanno ridefinendo ciò che è possibile fare con l’AI generativa. In questo articolo, analizzeremo in dettaglio le performance dei cinque modelli linguistici più avanzati attualmente disponibili:
- GPT-4.5 di OpenAI
- Claude 3.7 “Sonnet” di Anthropic
- Grok-3 di xAI
- DeepSeek R1 (modello open source)
- OpenAI o1 (specializzato in reasoning)
Ogni modello presenta punti di forza unici e si distingue in specifiche aree di applicazione. Approfondiamo le loro capacità attraverso i principali benchmark di settore.
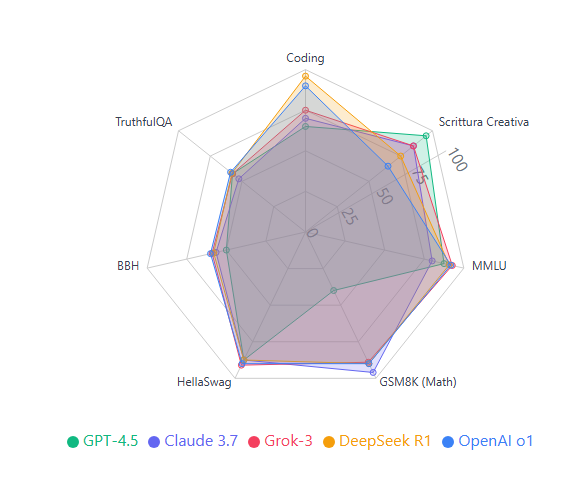
1. Capacità di Coding e Programmazione
Le performance di coding sono misurate principalmente attraverso benchmark come HumanEval e MBPP, che testano la capacità dei modelli di generare codice funzionante.
GPT-4.5 mostra buone capacità di coding, ma risulta inferiore ai modelli dotati di meccanismi di chain-of-thought (CoT). Senza un token di reasoning dedicato, le sue performance si attestano intorno a un pass@1 stimato del 60-65% [1].
Claude 3.7 Sonnet eccelle in questa categoria, raggiungendo pass@1 superiori al 70% nei benchmark specializzati, classificandosi come il migliore del gruppo [2]. Questo rappresenta un significativo miglioramento rispetto al suo predecessore, grazie all’introduzione di un sistema di ragionamento ibrido.
Grok-3 si posiziona ai vertici, con performance paragonabili a GPT-4. Su LiveCodeBench, ha addirittura superato GPT-4 con un punteggio di 57 contro 55 [3].
DeepSeek R1 si allinea ai migliori modelli, raggiungendo punteggi comparabili a o1. Ad esempio, su Codeforces ottiene il 96.3° percentile, appena superiore al 96.1 di o1 [4].
OpenAI o1, progettato specificamente per il reasoning, brilla nel coding complesso, posizionandosi nel top 11% su Codeforces [5], grazie al suo sistema di chain-of-thought interno.
2. Scrittura Creativa e Generazione di Testi
La creatività e naturalezza della scrittura è un aspetto fondamentale per molte applicazioni di AI generativa.
GPT-4.5 eccelle in questo campo, offrendo uno stile naturale, creativo ed empatico. OpenAI ha esplicitamente orientato questo modello verso interazioni più “umane” e coinvolgenti, definendolo un miglioramento in termini di “AI bestie” [6][7].
Claude 3.7 Sonnet offre prestazioni eccellenti, specialmente nella generazione di testi lunghi e coerenti, grazie alla sua capacità di gestire contesti fino a 200k token. Il ragionamento passo-passo controllabile lo rende ideale per trame complesse e strutturate [2].
Grok-3 presenta uno stile vivace, spiritoso e meno filtrato, con una personalità descritta come “ribelle” [3]. È risultato il preferito nei test di scrittura creativa su LMArena [8], apprezzato per il suo tono distintivo.
DeepSeek R1 produce contenuti corretti ma meno brillanti, con uno stile più orientato alla logica che alla creatività.
OpenAI o1 genera testi coerenti ma formali, privilegiando l’accuratezza e l’aderenza alle istruzioni rispetto alla creatività spontanea [6].
3. Conoscenza Generale (MMLU)
Il benchmark MMLU (Massive Multitask Language Understanding) valuta la conoscenza dei modelli su una vasta gamma di discipline.
Grok-3 ottiene i risultati migliori con un’accuratezza del 92,7% [2], posizionandosi al vertice del gruppo.
OpenAI o1 segue da vicino con il 91,8% [4].
DeepSeek R1 raggiunge il 90,8% [4], stabilendo lo stato dell’arte per i modelli open source.
GPT-4.5 si attesta tra l’85% e il 90% [1], superando GPT-4o di 5-10 punti percentuali.
Claude 3.7 Sonnet raggiunge circa l’80% [2], mostrando un miglioramento significativo rispetto a Claude 3.5, pur rimanendo leggermente indietro rispetto agli altri contendenti.
4. Capacità Matematiche (GSM8K)
Il benchmark GSM8K valuta la capacità di risolvere problemi matematici multi-step.
Claude 3.7 Sonnet eccelle, potendo raggiungere fino al 96% di accuratezza nei migliori casi [2], grazie alla sua capacità di ragionamento passo-passo.
DeepSeek R1 è specializzato in matematica avanzata, con un impressionante 91.6% sul benchmark MATH [5] e performance attese superiori al 90% su GSM8K.
OpenAI o1 è stato progettato specificamente per il reasoning, con capacità matematiche di livello “top solver” (top 500 AIME) [5].
Grok-3 risolve circa l’89% dei problemi [2], superando significativamente GPT-4o.
GPT-4.5 è relativamente più debole in questo ambito, faticando nei calcoli multi-step senza chain-of-thought. Ad esempio, ha ottenuto solo il 36.7% nell’esame AIME 2024 [9], rispetto al 50-55% di modelli come o1, R1 e Grok su prove simili [3].
5. Comprensione del Senso Comune (HellaSwag)
HellaSwag è un benchmark che valuta la capacità dei modelli di comprendere situazioni di senso comune.
Tutti i modelli analizzati ottengono punteggi molto alti (85-92%), con Grok-3 che si distingue leggermente con il 90-92% [8].
OpenAI o1 segue da vicino con l’88-92%.
GPT-4.5, Claude 3.7 Sonnet e DeepSeek R1 si attestano tutti intorno all’85-90%, con minime differenze tra loro [9].
Le elevate performance di tutti i modelli su questo benchmark indicano che la comprensione del senso comune è un’area in cui l’AI sta rapidamente avvicinandosi alle capacità umane.
6. Compiti Complessi (BigBench Hard)
BigBench Hard (BBH) propone problemi estremamente difficili e divergenti, mettendo alla prova i limiti dei modelli.
OpenAI o1 raggiunge circa il 60% di accuratezza, grazie al suo sistema di chain-of-thought.
Grok-3 e DeepSeek R1 si attestano intorno al 58-60% [10].
Claude 3.7 Sonnet ottiene il 55-58%, emergendo come il miglior modello su compiti difficili in alcuni test indipendenti [11].
GPT-4.5 si ferma intorno al 50%, limitato dalla mancanza di un ragionamento esplicito multi-turno.
7. Veridicità delle Informazioni (TruthfulQA)
TruthfulQA valuta la tendenza dei modelli a “inventare” informazioni non corrette.
Tutti i modelli mostrano una certa suscettibilità alle allucinazioni, con accuratezze che variano dal 50% al 60%.
OpenAI o1 ottiene circa il 58-60%, risultando altamente fattuale ma talvolta eccessivamente cauto.
GPT-4.5 (55-60%) ha ridotto significativamente le allucinazioni rispetto a GPT-4, con OpenAI che riporta un calo dal 61,8% al 37,1% [9].
Grok-3 (55-60%) mostra un leggero vantaggio su GPT-4o (52 vs 48 in test analoghi) [3].
DeepSeek R1 si attesta intorno al 58% [10].
Claude 3.7 Sonnet raggiunge il 50-55%, tendendo a risposte prudenti ma non completamente immuni da errori.
Confronto con Generazioni Precedenti
Claude 3.7 Sonnet rappresenta un notevole salto in avanti rispetto a Claude 3.5, introducendo un “ragionamento ibrido” che combina risposte rapide con la possibilità di pensare passo-passo quando necessario [2]. È più veloce e più efficace nei compiti di programmazione e logica, mantenendo la capacità di generare spiegazioni approfondite.
Grok-3 è stato definito da Elon Musk “un ordine di grandezza più capace di Grok-2” [12]. Con circa 2,7 trilioni di parametri e un sistema di “Think mode” opzionale, Grok-3 può funzionare sia come modello conversazionale veloce che come sistema di ragionamento profondo quando necessario [13].
Tabella Riassuntiva
| Categoria | GPT‑4.5 | Claude 3.7 “Sonnet” | Grok‑3 | DeepSeek R1 | OpenAI o1 |
|---|---|---|---|---|---|
| Coding | Buono (~65%) | Eccellente (≥70%) | Eccellente (57/100 LCB) | Eccellente (96.3 percentile) | Eccellente (top 11%) |
| Scrittura creativa | Molto elevata | Ottima | Ottima (stile vivace) | Buona | Discreta (formale) |
| MMLU | 85-90% | ~80% | 92.7% | 90.8% | 91.8% |
| GSM8K | Inferiore (~40%) | Molto alta (~96%) | ~89% | Altissima (90%+) | Altissima (90%+) |
| HellaSwag | 85-90% | 85-90% | 90-92% | 85-90% | 88-92% |
| BBH | ~50% | 55-58% | 58-60% | ~58% | ~60% |
| TruthfulQA | 55-60% | 50-55% | 55-60% | ~58% | 58-60% |
Conclusioni
Il panorama dei modelli AI di ultima generazione offre una varietà di soluzioni ottimizzate per diverse esigenze:
- GPT-4.5 eccelle nella scrittura creativa e nelle interazioni naturali, risultando ideale per applicazioni rivolte agli utenti finali che richiedono un tocco “umano”.
- Claude 3.7 Sonnet offre un ottimo equilibrio tra velocità e profondità di ragionamento, con particolare forza nel coding e nella gestione di contesti lunghi.
- Grok-3 emerge come leader in molti benchmark quantitativi (MMLU, HellaSwag) e offre uno stile distintivo più informale e creativo.
- DeepSeek R1 rappresenta un’eccellente opzione open source con performance paragonabili ai modelli proprietari, particolarmente forte in matematica e coding.
- OpenAI o1 domina nei compiti che richiedono ragionamento profondo, come matematica avanzata e coding complesso, grazie al suo sistema di chain-of-thought interno.
La scelta del modello ottimale dipende quindi dalle specifiche esigenze applicative: comunicazione empatica (GPT-4.5), ragionamento ibrido efficiente (Claude 3.7), performance di punta con stile distintivo (Grok-3), soluzione open source di alta qualità (DeepSeek R1), o massima capacità di ragionamento (OpenAI o1).
Fonti
[1] https://www.anybodycanprompt.com/p/the-ultimate-ai-showdown-gpt-45-vs [Confronto dettagliato tra GPT-4.5, Claude 3.7 e Grok-3 con focus sulle performance]
[2] https://www.anybodycanprompt.com/p/the-ultimate-ai-showdown-gpt-45-vs [Analisi del ragionamento step-by-step di Claude 3.7 Sonnet]
[3] https://www.ccn.com/education/crypto/grok-3-vs-gpt-4-key-differences-explained/ [Confronto diretto tra Grok-3 e GPT-4 con evidenza delle differenze chiave]
[4] https://textcortex.com/post/deepseek-r1-review [Recensione approfondita delle performance di DeepSeek R1 su vari benchmark]
[5] https://blog.promptlayer.com/openai-vs-deepseek-an-analysis-of-r1-and-o1-models/ [Analisi comparativa tra OpenAI o1 e DeepSeek R1]
[6] https://cointelegraph.com/news/openai-gpt4-5-wont-blow-your-mind-but-could-be-friend [Analisi dell’orientamento di GPT-4.5 verso interazioni più naturali]
[7] https://cointelegraph.com/news/openai-gpt4-5-wont-blow-your-mind-but-could-be-friend [Comunicato OpenAI sulle caratteristiche di GPT-4.5]
[8] https://www.helicone.ai/blog/grok-3-benchmark-comparison [Analisi tecnica di Grok-3 con focus sui benchmark di performance]
[9] https://felloai.com/it/2025/02/openais-gpt%E2%80%914-5-finally-arrived-can-it-beat-grok-3-and-claude-3-7/ [Confronto tra GPT-4.5, Grok-3 e Claude 3.7 su benchmark specifici]
[10] https://huggingface.co/neuralmagic/DeepSeek-R1-Distill-Qwen-32B-quantized.w4a16 [Dati tecnici su DeepSeek R1 e sue versioni distillate]
[11] https://dev.to/mehmetakar/claude-37-sonnet-benchmark-with-chatgpt-o1-o3-mini-high-deepseek-r1-grok-3-4fda [Benchmark indipendente di Claude 3.7 Sonnet a confronto con altri modelli]
[12] https://www.capacitymedia.com/article/grok-3-shatters-ai-benchmarks-as-musks-xai-takes-aim-at-openai [Dichiarazioni di Elon Musk su Grok-3 e sue capacità]
[13] https://www.datacamp.com/blog/grok-3 [Analisi tecnica delle caratteristiche di Grok-3 e del suo “Think mode”]

Leave a comment