
Ottimizzazione dell’Utilizzo di LM Studio in Ambienti Educativi con Risorse Limitate
Introduzione
Nell’era dell’intelligenza artificiale, strumenti come LM Studio offrono opportunità uniche per l’apprendimento e la ricerca. Tuttavia, in contesti educativi con risorse hardware limitate, è fondamentale implementare strategie che massimizzino l’efficienza e l’accessibilità. Questo articolo illustra una metodologia per l’utilizzo condiviso di LM Studio, ottimizzando le risorse disponibili e garantendo un’esperienza formativa efficace.
Vincoli Tecnici e Necessità di una Strategia Condivisa
LM Studio richiede specifiche hardware elevate per funzionare in modo ottimale, tra cui:
- Processore: Supporto per il set di istruzioni AVX2.
- RAM: Almeno 16 GB.
- GPU: Scheda grafica dedicata NVIDIA o AMD con almeno 8 GB di VRAM.
In molti istituti scolastici, non è praticabile dotare ogni studente di una macchina con tali specifiche. Pertanto, l’implementazione di una strategia che consenta l’accesso condiviso a un server LM Studio centralizzato diventa essenziale.
Strategia Proposta: Accesso Sequenziale e Preparazione dei Prompt
Per ottimizzare l’utilizzo di LM Studio in un ambiente multiutente, si propone la seguente metodologia:
- Suddivisione in Gruppi: Organizzare gli studenti in gruppi numerati (ad esempio, Gruppo 1, Gruppo 2, ecc.).
- Preparazione dei Prompt: Ogni gruppo prepara anticipatamente una serie di N prompt, salvandoli in un file di testo.
- Turni di Accesso: Stabilire un calendario che assegni a ciascun gruppo un intervallo di tempo specifico per l’accesso al server LM Studio.
- Invio dei Prompt: Durante il proprio turno, il gruppo invia 2-3 prompt al server, con un tempo di elaborazione stimato tra 10 e 15 minuti.
- Analisi Offline: Nei periodi di inattività, i gruppi analizzano le risposte ricevute, preparando eventuali domande di follow-up per il turno successivo.
Implementazione Tecnica: Estensione per l’Accesso al Server LM Studio
Per facilitare l’interazione con il server LM Studio, è possibile utilizzare un’estensione che consente agli utenti di inviare prompt e ricevere risposte in modo efficiente. Di seguito, forniamo i file necessari per l’installazione e l’utilizzo dell’estensione.
Vantaggi della Strategia Proposta
- Ottimizzazione delle Risorse: L’accesso sequenziale al server centralizzato consente di sfruttare al meglio le risorse hardware disponibili, evitando sovraccarichi e garantendo tempi di risposta adeguati.
- Collaborazione e Apprendimento: La suddivisione in gruppi e la preparazione anticipata dei prompt promuovono la collaborazione tra gli studenti e un approccio più riflessivo all’apprendimento.
- Scalabilità: Questa metodologia può essere adattata a diverse dimensioni di classi e a vari contesti educativi, rendendola una soluzione flessibile per l’integrazione di LM Studio nell’ambiente scolastico.
Conclusione
L’integrazione di strumenti avanzati come LM Studio nell’educazione richiede un’attenta pianificazione e strategie che tengano conto delle limitazioni hardware. La metodologia proposta offre una soluzione pratica per massimizzare l’accesso e l’efficacia dell’apprendimento, garantendo che tutti gli studenti possano beneficiare delle potenzialità dell’intelligenza artificiale.
Appendice i 4 file necessari in una cartella da caricare su chrome:
manifest.json
{
"manifest_version": 3,
"name": "Streaming Chat API",
"version": "1.0",
"description": "Chat with the streaming AI model and set custom parameters.",
"permissions": ["storage"],
"host_permissions": [
"http://127.0.0.1:1234/*"
],
"background": {
"service_worker": "background.js"
},
"action": {
"default_popup": "popup.html"
}
}background.js
chrome.runtime.onInstalled.addListener(() => {
console.log('Extension installed');
});popup.html
<!DOCTYPE html>
<html>
<head>
<title>LLM Chat</title>
<style>
body {
width: 800px;
height: 600px;
padding: 20px;
font-family: system-ui, -apple-system, sans-serif;
}
.container {
display: flex;
flex-direction: column;
gap: 15px;
}
.input-group {
display: flex;
flex-direction: column;
gap: 5px;
}
input, textarea {
padding: 8px;
border: 1px solid #ccc;
border-radius: 4px;
font-size: 14px;
}
textarea {
min-height: 80px;
resize: vertical;
}
.button-group {
display: flex;
gap: 10px;
}
button {
padding: 8px 16px;
border: none;
border-radius: 4px;
cursor: pointer;
font-size: 14px;
}
#startChat {
background: #0066cc;
color: white;
}
#stopChat {
background: #dc3545;
color: white;
}
#response {
border: 1px solid #ccc;
border-radius: 4px;
padding: 15px;
min-height: 200px;
max-height: 400px;
overflow-y: auto;
white-space: pre-wrap;
font-family: monospace;
font-size: 14px;
}
h2 {
margin: 0 0 20px 0;
}
</style>
</head>
<body>
<div class="container">
<h2>Chat with Model</h2>
<div class="input-group">
<label for="model">Model:</label>
<input type="text" id="model" value="meta-llama-3.1-8b-instruct@q8_0">
</div>
<div class="input-group">
<label for="temperature">Temperature:</label>
<input type="number" id="temperature" step="0.1" min="0" max="2" value="0.7">
</div>
<div class="input-group">
<label for="systemPrompt">System Prompt:</label>
<textarea id="systemPrompt">Rispondi in italiano. Adegua la risposta per un bambino di 10 anni. Usa un tono giocoso, informale e simpatico.</textarea>
</div>
<div class="input-group">
<label for="userPrompt">User Prompt:</label>
<textarea id="userPrompt">Chi era Napoleone?</textarea>
</div>
<div class="button-group">
<button id="startChat">Start Chat</button>
<button id="stopChat">Stop</button>
</div>
<div id="response"></div>
</div>
http://popup.js
</body>
</html>popup.js
let controller = null;
document.addEventListener('DOMContentLoaded', function() {
const startButton = document.getElementById('startChat');
const stopButton = document.getElementById('stopChat');
const responseDiv = document.getElementById('response');
// Load saved values from storage
chrome.storage.local.get(['model', 'temperature', 'systemPrompt', 'userPrompt'], function(data) {
if (data.model) document.getElementById('model').value = data.model;
if (data.temperature) document.getElementById('temperature').value = data.temperature;
if (data.systemPrompt) document.getElementById('systemPrompt').value = data.systemPrompt;
if (data.userPrompt) document.getElementById('userPrompt').value = data.userPrompt;
});
// Save input values when they change
['model', 'temperature', 'systemPrompt', 'userPrompt'].forEach(id => {
document.getElementById(id).addEventListener('change', function(e) {
chrome.storage.local.set({ [id]: e.target.value });
});
});
async function streamChat() {
try {
// Abort any existing request
if (controller) {
controller.abort();
}
// Create new controller and clear response
controller = new AbortController();
responseDiv.textContent = '';
// Get current values
const model = document.getElementById('model').value;
const temperature = parseFloat(document.getElementById('temperature').value);
const systemPrompt = document.getElementById('systemPrompt').value;
const userPrompt = document.getElementById('userPrompt').value;
const response = await fetch('http://127.0.0.1:1234/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
model: model,
messages: [
{role: "system", content: systemPrompt},
{role: "user", content: userPrompt}
],
temperature: temperature,
max_tokens: -1,
stream: true
}),
signal: controller.signal
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const {value, done} = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
const lines = chunk.split('\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
const jsonStr = line.slice(6);
if (jsonStr === '[DONE]') continue;
try {
const jsonData = JSON.parse(jsonStr);
const content = jsonData.choices[0]?.delta?.content || '';
responseDiv.textContent += content;
} catch (e) {
console.error('JSON parse error:', e);
}
}
}
}
} catch (error) {
if (error.name === 'AbortError') {
console.log('Request aborted');
} else {
responseDiv.textContent = 'Error: ' + error.message;
}
} finally {
controller = null;
}
}
startButton.addEventListener('click', streamChat);
stopButton.addEventListener('click', () => {
if (controller) {
controller.abort();
}
});
});127.0.0.1 deve essere sostituito con l’IP del server dove e’ installato LMStudio. Questo deve essere lanciato con la finestra
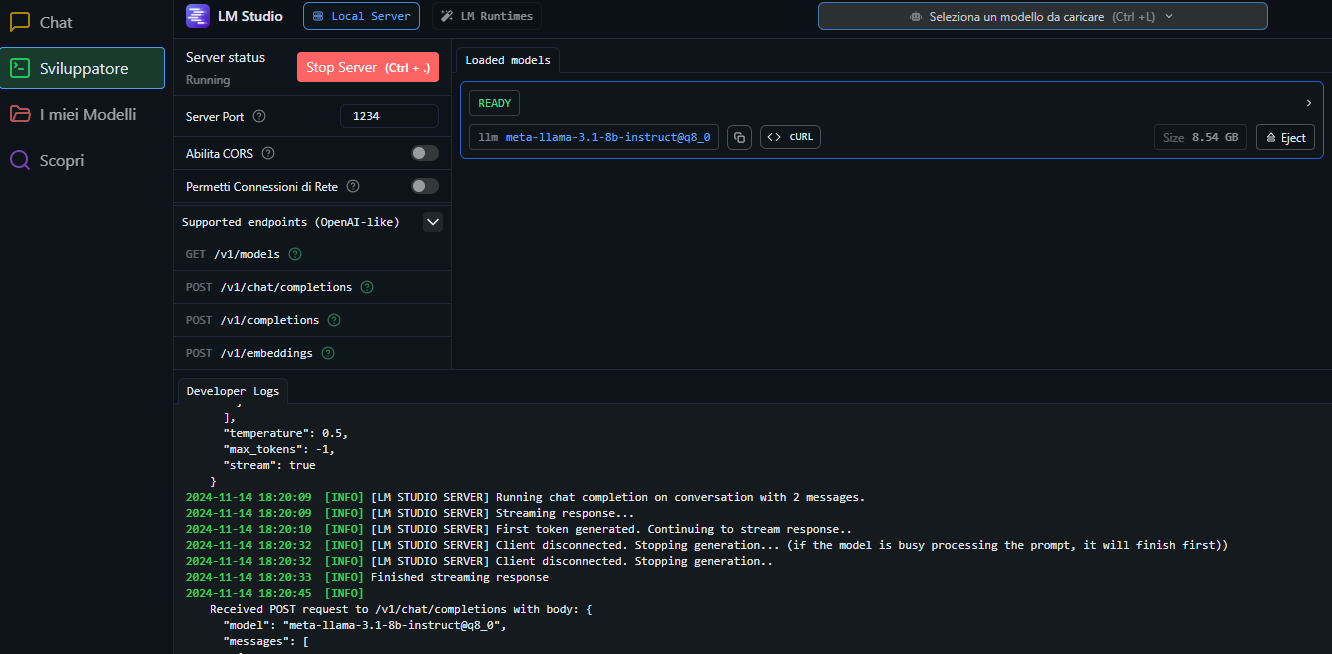
Il modello caricato come si vede deve essere meta-llama-3.1-8b-Instruct@q8_0, con una lunghezza di contesto adeguata per le domande che si intendono fare, una ottima lunghezza e’ 16000 token, ma per domande piu’ semplici 4000 o 8000 dovrebbero bastare e sono anche piu’ rapide.
se si usa un modello differente deve essere adeguato popup.js per ogni gruppo.
Ogni gruppo vedra’ questa interfaccia una volta caricata l’estensione non pacchettizzata dal menu chrome://extensions e specificando la cartella che contiene i 4 files, e avere abilitato la visualizzazione del tasto dell’estensione in alto a dx
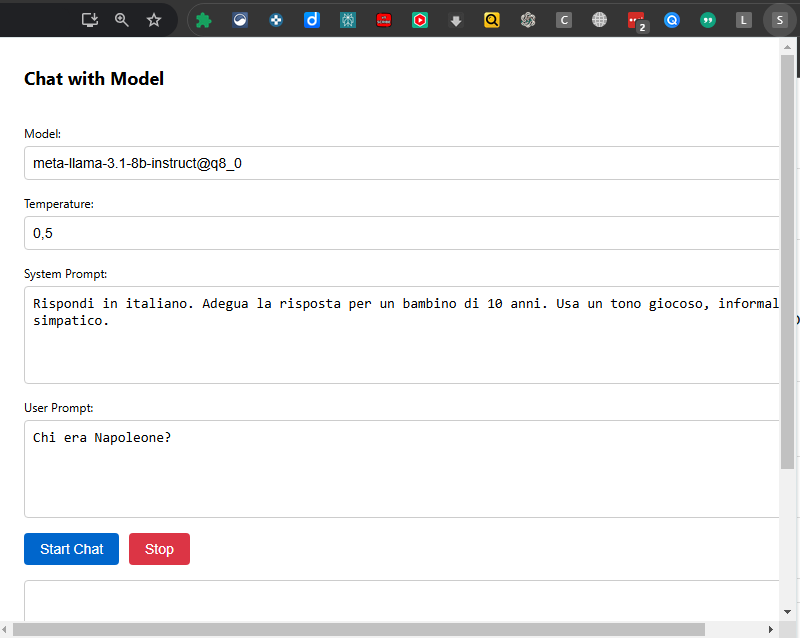
si noti che e’ possibile impostare il system prompt e il prompt, per avere risposte coerenti con l’incontro della volta scorsa.

Leave a comment