Introduzione
Negli ultimi anni, i Modelli di Linguaggio di Grandi Dimensioni (LLM) come ChatGPT hanno rivoluzionato il modo in cui interagiamo con la tecnologia. Tuttavia, c’è una percezione diffusa secondo cui questi modelli funzionino in modo simile alla fisica quantistica, ovvero siano intrinsecamente aleatori e imprevedibili, con fenomeni come le “allucinazioni” considerate esempi di comportamenti non deterministici. In realtà, il funzionamento dei LLM è molto più strutturato e deterministico di quanto si possa pensare. In questo articolo, esploreremo come funzionano realmente i LLM, spiegando in termini semplici concetti come temperatura, top_p e top_k, e demistificheremo l’idea che l’aleatorietà sia alla base delle loro risposte.
Capitolo 1: Comprendere il Funzionamento dei LLM e l’Architettura Transformer
I Modelli di Linguaggio di Grandi Dimensioni, come GPT-4, si basano su un’architettura chiamata Transformer. Ma cosa significa realmente?
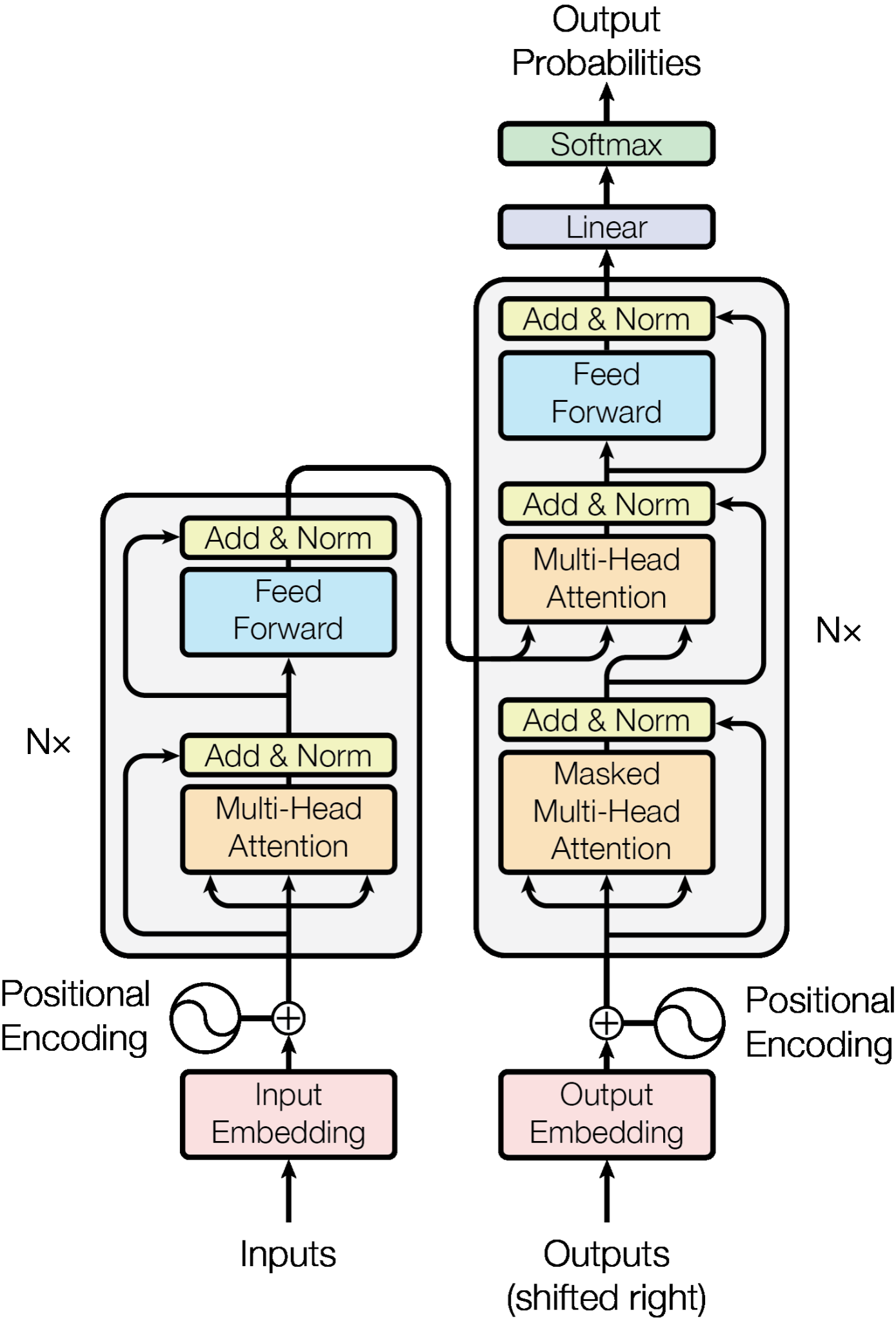
L’Architettura Transformer: Semplicemente Somme e Moltiplicazioni
Immagina il Transformer come una gigantesca rete di calcoli matematici. Alla base, utilizza operazioni come somme e moltiplicazioni per elaborare e comprendere il linguaggio. Quando inserisci una frase nel modello, questa viene suddivisa in parole o frammenti chiamati token. Ogni token passa attraverso diversi strati del Transformer, dove vengono applicate combinazioni di somme e moltiplicazioni per determinare il significato e il contesto.
Dettagli Semplici: Come “Pensano” i Transformers
- Input Tokenization: La frase viene spezzettata in token.
- Embedding: Ogni token viene trasformato in un vettore numerico che rappresenta il suo significato.
- Attenzione (Self-Attention): Il modello valuta quali parti della frase sono più rilevanti tra loro.
- Feed-Forward Networks: Applicazione di somme e moltiplicazioni per elaborare le informazioni.
- Output Generation: Il modello prevede il prossimo token basandosi sui calcoli effettuati.
Tutto questo avviene in modo altamente strutturato e deterministico. Ogni operazione è basata su algoritmi matematici precisi, garantendo coerenza e affidabilità nelle risposte generate.
L’Elemento di Stocasticità: Dove entra la “Casualità”
Nonostante tutta questa struttura, c’è un elemento di casualità introdotto nella fase finale della generazione del testo. Questo serve a rendere le risposte più variegate e “umane”. È qui che entrano in gioco parametri come temperatura, top_p e top_k, che influenzano quanto il modello possa “scegliere” tra diverse opzioni di parole.
Capitolo 2: Parametri di Generazione del Testo: Temperatura, Top_p e Top_k
Per comprendere meglio come i LLM generano risposte, è fondamentale conoscere alcuni parametri chiave: temperatura, top_p e top_k. Questi controllano l’elemento di casualità e determinano la natura delle risposte prodotte.
Temperatura: Controllare la Creatività
- Cos’è la Temperatura? La temperatura è un parametro che regola la “creatività” delle risposte. Varia tipicamente tra 0 e 1.
- Come Funziona?
- Temperatura Bassa (es. 0): Il modello tende a scegliere le parole più probabili, rendendo le risposte più coerenti e prevedibili.
- Temperatura Alta (es. >1): Aumenta la varietà delle parole scelte, rendendo le risposte più creative e meno prevedibili.
- Perché è Importante? Impostando la temperatura a 0, si elimina quasi completamente la casualità, assicurando risposte sempre identiche per lo stesso input.
Top_p (Nucleus Sampling): Limitare il Cono di Probabilità
- Cos’è Top_p? Top_p, o nucleus sampling, considera solo le parole che, sommate insieme, raggiungono una certa probabilità p.
- Come Funziona?
- Top_p = 1: Include tutte le parole possibili, senza restrizioni.
- Top_p Basso: Limita la scelta a un sottoinsieme di parole altamente probabili, riducendo la casualità.
- Perché è Importante? Regolare top_p permette di controllare quanto il modello possa esplorare opzioni meno probabili, bilanciando coerenza e varietà.
Top_k: Limitare il Numero di Opzioni
- Cos’è Top_k? Top_k limita il numero di parole tra cui il modello può scegliere, selezionando solo le k parole più probabili.
- Come Funziona?
- Top_k = 0 o Disabilitato: Nessuna restrizione, tutte le parole sono considerate.
- Top_k Basso: Solo le parole più probabili vengono scelte, aumentando la determinismo.
- Perché è Importante? Similarmente a top_p, top_k aiuta a controllare la varietà delle risposte, ma lo fa limitando il numero di scelte possibili.
Combinazione dei Parametri per Risposte Deterministiche
Per garantire che il modello fornisca sempre la stessa risposta per un dato input, indipendentemente dalle chiamate successive, è possibile impostare i parametri nel seguente modo:
- Temperatura = 0: Elimina la casualità nella scelta delle parole.
- Top_p = 1: Considera tutte le parole possibili.
- Top_k = 0 o Disabilitato: Non limita il numero di parole considerate.
Questa combinazione assicura che, dato un input specifico, il modello seguirà sempre lo stesso percorso deterministico per generare la risposta, evitando variazioni casuali.
Conclusione
Contrariamente a quanto molti pensano, i Modelli di Linguaggio di Grandi Dimensioni non funzionano come la fisica quantistica, basandosi su principi di casualità intrinseca. Al contrario, la loro architettura Transformer si fonda su operazioni matematiche determinate, come somme e moltiplicazioni, per elaborare e generare il linguaggio. L’elemento di stocasticità introdotto tramite parametri come temperatura, top_p e top_k serve principalmente a rendere le risposte più variate e simili a quelle umane, ma può essere regolato per ottenere risposte altamente coerenti e ripetibili. Comprendere questi meccanismi non solo demistifica il funzionamento dei LLM, ma permette anche di utilizzarli in modo più efficace, adattando le loro risposte alle esigenze specifiche degli utenti.

Leave a comment